
Why Your Software Engineering Experience is Your Greatest Asset in AI
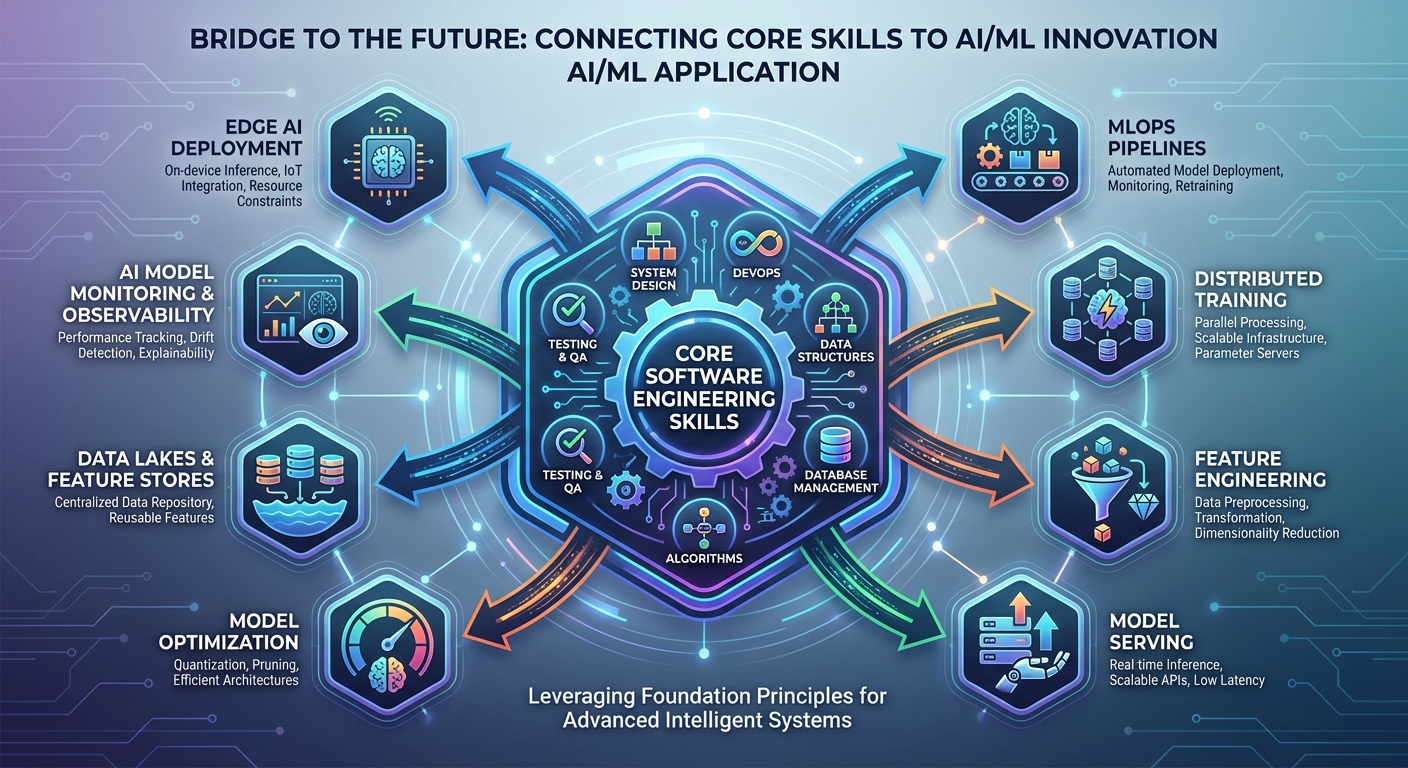
As you stand at the crossroads of your career, contemplating a move into artificial intelligence, a single question likely echoes in your mind: "Is my software engineering experience even useful?" The answer is an emphatic and unequivocal yes. In fact, your background isn't just useful it's your single greatest advantage, providing a solid foundation that many aspiring AI practitioners lack.
The journey into an AI career path for a developer isn't about starting from scratch; it's about translating your hard won expertise. While you'll need to learn data science basics and deep learning fundamentals, your core engineering skills will accelerate your progress and make you an invaluable asset in building real world AI systems. Let's break down how.
From System Design to AI Architecture
Think about the last time you designed a scalable, resilient system using microservices. You considered load balancing, API gateways, service discovery, and database sharding to ensure the application could handle thousands of concurrent users. Now, apply that same thinking to AI:
- Distributed Training: Training a massive model like a Large Language Model (LLM) can't be done on a single machine. It requires a distributed system that can split the workload across a cluster of GPUs. Your experience with distributed computing and container orchestration tools like Kubernetes is directly applicable here.
- Inference at Scale: Once a model is trained, it needs to be deployed to serve predictions. Building a low latency, high throughput inference service is a classic system design problem. Your knowledge of caching strategies, message queues (like RabbitMQ or Kafka), and building robust APIs is precisely what's needed to take a model from a research notebook to a production ready product.
This is a core part of any practical machine learning roadmap; you're not just building a model, you're building the robust infrastructure that powers it.
The Natural Leap from DevOps to MLOps
If you've ever set up a CI/CD pipeline, you're already halfway to understanding MLOps (Machine Learning Operations). The goal is the same: automate, monitor, and ensure quality. The principles you live by in DevOps translate directly, making the world of AI for software developers far more accessible.
Consider these parallels:
| DevOps Practice | MLOps Equivalent |
|---|---|
| Versioning code with Git | Versioning models, data, and code with tools like DVC and MLflow |
| Continuous Integration (CI) | Automated model validation and testing on new data |
| Continuous Deployment (CD) | Automated model retraining and deployment pipelines |
| Monitoring application performance | Monitoring for model drift, data skew, and prediction accuracy |
A 2021 study by Algorithmia found that it takes companies an average of several months to deploy a single machine learning model. This bottleneck is almost always due to a lack of MLOps expertise. As a software engineer, you have the skills to bridge this gap, a critical need in the industry.
The Unsung Hero: Clean Code and Abstraction
The world of AI is filled with experimental code, often written in Jupyter notebooks. While excellent for exploration, this code is rarely ready for production. This is where your engineering discipline becomes a superpower.
When you begin your journey with Python for AI, your instinct to write modular, testable, and well documented code is invaluable. An AI system isn't just a single model; it's a complex web of data ingestion pipelines, feature engineering scripts, training loops, and inference APIs. Writing clean, abstracted code is essential for:
- Reproducibility: Ensuring that experiments can be repeated reliably.
- Collaboration: Allowing team members to understand and build upon your work.
- Maintainability: Making it possible to debug, update, and improve the system over time.
Your ability to refactor a messy notebook into a clean, object oriented Python package is a skill that sets you apart and is fundamental to building AI that works in the real world.
The Debugging Mindset in a World of Uncertainty
Finally, consider your approach to debugging. When a traditional application fails, you trace the logic, check the logs, and find the deterministic bug. Debugging an AI model is different. Why did the model's accuracy suddenly drop? Why is it making a bizarre prediction for a specific input?
The cause is often non deterministic and can stem from a wide range of issues: a subtle shift in the input data (data drift), a poorly chosen hyperparameter, or a bug in the data preprocessing pipeline. Your systematic, methodical debugging process isolating variables, forming hypotheses, and running controlled tests is the exact mindset needed to troubleshoot these complex, probabilistic systems.
Ultimately, the path to learn machine learning is far shorter for you. You've already mastered the principles of building robust, scalable, and maintainable software. Your extensive AI learning roadmap for software professionals is simply about layering new concepts like statistics, model architectures, and data analysis on top of the powerful engineering foundation you already possess.
Phase 1: Building a Rock Solid Foundation in Math and Python for AI
Before you can architect sophisticated neural networks or deploy cutting edge models, you must first build an unshakable foundation. This is the most critical phase in any AI learning roadmap, and for good reason: it’s where you translate abstract concepts into practical, code based intuition. As a software engineer, you already have a significant head start in logical thinking and coding. Now, let's channel that advantage by focusing on the essential prerequisites for learning AI.
This phase isn't about becoming a theoretical mathematician; it's about becoming a pragmatic AI practitioner. We'll bypass the dense academic proofs and focus on the applied knowledge you need to understand why your code works, not just that it works.
Applied Mathematics for Developers: The "Why" Behind the Code
Many aspiring AI developers are intimidated by the math. Don't be. Your goal is to build an intuitive understanding of three key areas, which form the bedrock of nearly all data science basics and machine learning.
- Linear Algebra: The Language of Data
At its core, linear algebra is the study of vectors and matrices. In the world of AI, this is how we represent and manipulate data. Think of it this way:
- A vector is simply a list of numbers that can represent a single data point. For example, a user's profile could be a vector:
[age, login_count, purchase_amount]. - A matrix is a collection of vectors, or a 2D grid of numbers. An entire dataset of users can be represented as a matrix, where each row is a user (a vector) and each column is a feature.
- An image is just a 3D matrix (or tensor), with dimensions for height, width, and color channels (RGB).
- A vector is simply a list of numbers that can represent a single data point. For example, a user's profile could be a vector:
Understanding these concepts is fundamental because every operation in a neural network from processing input data to updating model weights is a series of highly optimized matrix operations. You don't need to compute determinants by hand, but you do need to understand what a dot product represents and why matrix dimensions must match.
- Calculus: The Engine of Learning If linear algebra is how we represent data, calculus is how models learn from it. The single most important concept to grasp is gradient descent. Imagine you're standing on a foggy mountain and need to find the lowest point in the valley. You'd look at your feet, find the steepest downward path, and take a small step in that direction. You'd repeat this process until you couldn't go any lower.
That's gradient descent. The "slope" is the derivative (or gradient), and the "valley floor" is the point where your model's error is minimized. This is one of the most important deep learning fundamentals. You don't need to be a calculus wizard, but understanding this core optimization algorithm is non negotiable for anyone serious about wanting to learn machine learning.
- Probability & Statistics: The Reality Check
How do you know if your model is actually any good? How do you measure its performance and interpret its predictions? That's where statistics comes in. It's the framework for evaluating your work and making data driven decisions. Key concepts for AI for software developers include:
- Descriptive Statistics: Mean, median, and standard deviation to understand your data's distribution.
- Probability Distributions: Understanding common patterns in data, like the Normal (or Gaussian) distribution.
- Evaluation Metrics: Concepts like accuracy, precision, recall, and the F1 score to measure how well a classification model is performing. A model with 99% accuracy might sound great, but if it's for fraud detection, what really matters is how well it catches the rare fraudulent cases (recall).
Python for AI: Mastering Your Primary Toolset
Knowing basic Python syntax is the starting point, not the finish line. The true power of Python for AI lies in its rich ecosystem of specialized libraries. Your machine learning roadmap must include mastering these workhorses:
- NumPy (Numerical Python): This is the foundational library for numerical computing in Python. It provides a high performance multidimensional array object and tools for working with these arrays. It's so efficient because its core operations are written in C, allowing it to perform mathematical operations on large datasets far faster than native Python lists.
- Pandas: If NumPy is the foundation, Pandas is the framework for data manipulation and analysis. It introduces the
DataFrame, a two dimensional, size mutable, and potentially heterogeneous tabular data structure with labeled axes (rows and columns). Think of it as a spreadsheet or SQL table that you can programmatically control perfect for cleaning, transforming, and analyzing real world data. - Matplotlib & Seaborn: You can't fix what you can't see. These are the premier data visualization libraries. Matplotlib is the low level, highly customizable tool for creating any plot imaginable. Seaborn is built on top of Matplotlib and provides a high level interface for drawing attractive and informative statistical graphics. Visualizing your data is the first step in understanding it.
Setting Up Your Development Environment
A craftsman is only as good as their workshop. For an AI for software engineers professional, a well configured environment is crucial for productivity.
- Manage Dependencies with Conda or venv: To avoid the infamous "dependency hell," always use a virtual environment.
venvis built into Python and is great for general development. However, Conda is often preferred in data science because it manages both Python and non Python packages (like the CUDA toolkit for GPU computing) and their complex dependencies seamlessly. - Choose Your IDE: Jupyter vs. VS Code:
- Jupyter Notebooks/Lab: The go to tool for exploration, experimentation, and visualization. Its cell based execution model is perfect for iterating quickly and documenting your thought process with text, code, and output in one place.
- VS Code: An outstanding, full featured code editor. With its powerful Python and Jupyter extensions, it offers the best of both worlds: you can run notebooks for exploration and then easily refactor that code into reusable
.pyscripts for production systems, all within a single application.
This dual tool approach is a common workflow that supports the entire journey from initial idea to production ready code, a vital part of any AI career path. This structured approach is a cornerstone of our extensive AI learning roadmap for software professionals, ensuring you build skills that are both powerful and practical.
Phase 2: Mastering Core Machine Learning Concepts
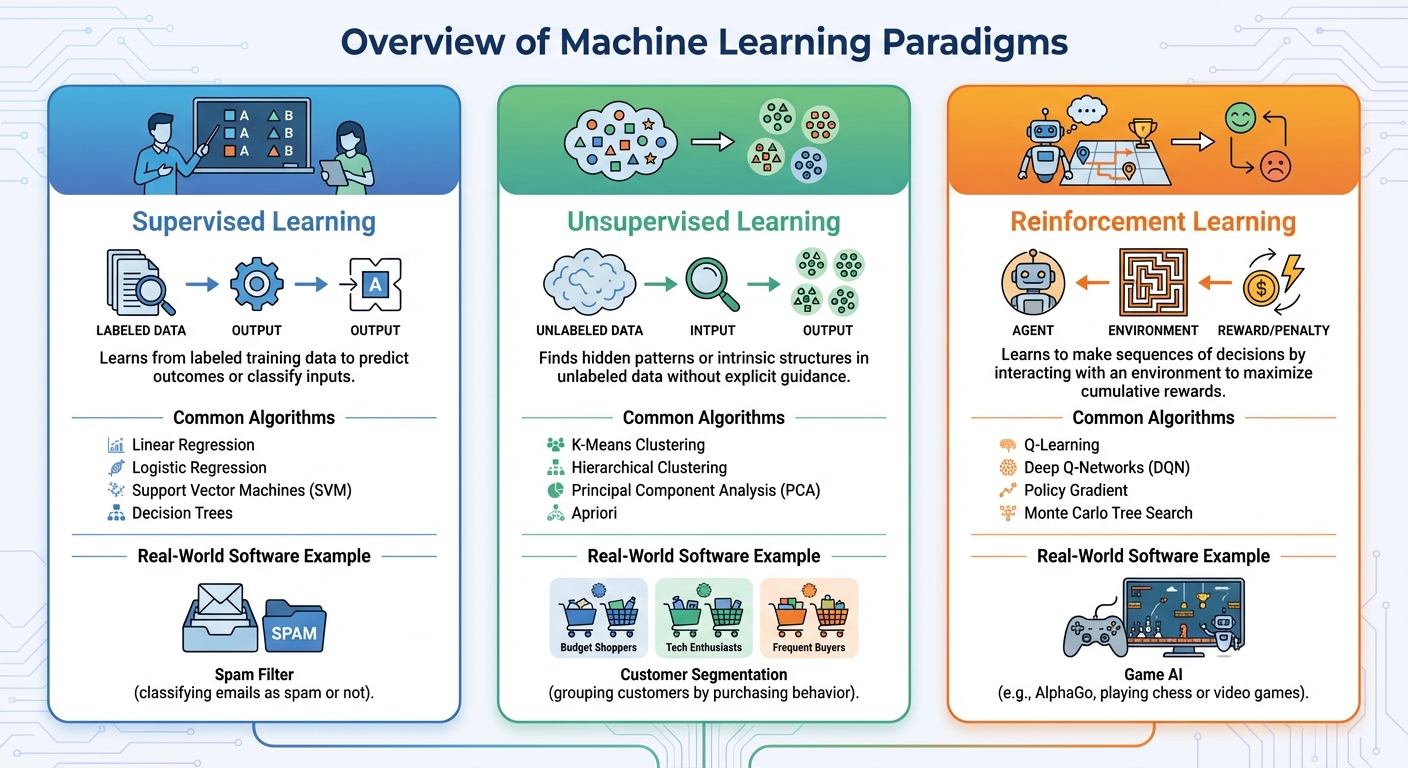
With your rock solid foundation in Python and mathematics from Phase 1, you've essentially built the perfect workshop. You have the tools, the raw materials (data), and the logical framework. Now, it's time to become the master craftsman. This phase of your AI learning roadmap is where you'll learn the core techniques to transform raw data into intelligent action. We're moving beyond syntax and into the very soul of how machines learn.
As a software engineer, you're used to writing explicit instructions. You design algorithms with clear, deterministic steps. Machine learning flips this paradigm: you provide the data and the desired outcome, and the algorithm infers the rules. This section will demystify the three primary ways it accomplishes this, building the intuition that is essential for any professional on an AI career path.
Supervised Learning: Learning with an Answer Key
Imagine you're training a junior developer. You wouldn't just give them a pile of code; you'd give them code examples (the input) and explain what each one does (the output or "label"). Supervised learning works exactly the same way. It's the most common and intuitive type of machine learning, where you train a model on a dataset that is fully labeled.
Think of it as creating a "smart function" that you don't have to code yourself. Your goal is to learn a mapping function f(X) = y, where you can later provide new, unseen inputs X and have the model predict the output y. This is one of the most powerful concepts in the field of AI for software engineers.
Supervised learning is primarily split into two types of problems:
-
Regression (Predicting a Value): This is for when your target
yis a continuous numerical value. You're not asking "if," you're asking "how much?"- Real World Example: Predicting user churn isn't just a "yes/no" question. A better regression model might predict the probability of a user churning in the next 30 days (e.g., 0.85), or predict a customer's lifetime value (LTV).
- Key Algorithms: Linear Regression is the "hello world" of this domain. It finds the best fit line through your data points to make predictions.
-
Classification (Predicting a Category): This is for when your target
yis a discrete label. You're asking "which one?" or "is it A, B, or C?"- Real World Example: A support system that automatically classifies incoming tickets as 'Billing', 'Technical Issue', or 'Feature Request'. This allows for faster routing and resolution, a direct application of AI for software developers in a business context.
- Key Algorithms:
- Logistic Regression: Despite its name, it's used for classification, predicting the probability that an input belongs to a certain class.
- Decision Trees: These are incredibly intuitive for developers, as they mirror a series of
if-elsestatements that the model learns from the data. - Support Vector Machines (SVMs): These find the optimal "decision boundary" that best separates the different classes in your data.
Unsupervised Learning: Finding a Signal in the Noise
Now, imagine you're given a database with a billion user interaction logs but no labels. No one has told you which users are "power users" or which server events are "anomalies." This is the domain of unsupervised learning the art of finding hidden structures and patterns in unlabeled data. It’s a core component of data science basics.
-
Clustering (Grouping Similar Things): The goal of clustering is to partition your data into distinct groups where items in the same group are more similar to each other than to those in other groups.
- Real World Example: Customer segmentation. An e commerce company could use an algorithm like K Means to analyze purchasing behavior and automatically group customers into segments like 'Bargain Hunters', 'Brand Loyalists', or 'Seasonal Shoppers'. This allows for highly targeted marketing without manually creating these labels.
- Software Analogy: Think of it as a tool that automatically refactors a messy codebase by grouping related functions and classes into modules.
-
Dimensionality Reduction (Simplifying the Data): Often, your data has hundreds or even thousands of features (dimensions). This can make it slow to process and difficult to visualize. Dimensionality reduction techniques, like Principal Component Analysis (PCA), intelligently compress your data by finding the most important underlying patterns, discarding the noise.
- Real World Example: Anomaly detection in network traffic. By reducing the complexity of the data, you can more easily spot deviations from the norm that might indicate a security breach or system failure.
Reinforcement Learning: Learning from Consequences
Reinforcement Learning (RL) is a different beast altogether. It's not about labeled data or hidden patterns; it's about learning optimal behavior through trial and error. An "agent" (your algorithm) performs "actions" in an "environment" to maximize a cumulative "reward."
- The Agent Environment Loop: The agent observes the state of the environment, takes an action, and receives a reward (or penalty). It repeats this loop millions of times, slowly learning a "policy" a strategy that dictates the best action to take in any given state.
- Analogy for Developers: This is the ultimate self optimizing system. Imagine a load balancer (the agent) that doesn't just use a round robin algorithm. Instead, it observes server response times and CPU load (the environment state), decides which server to route traffic to (the action), and gets a reward for low latency and a penalty for dropped requests. Over time, it learns a sophisticated routing policy that adapts to real time conditions.
- Beyond Games: While famous for mastering games like Go and StarCraft, RL is used to optimize everything from robotic control systems and supply chain logistics to managing data center energy consumption.
The Two Pillars of a Robust Model
As you learn machine learning, you'll quickly realize that building a model is easy, but building a good model is hard. Two concepts are critical for every engineer to internalize.
1. The Bias Variance Tradeoff
This is one of the most fundamental concepts in machine learning. It's the delicate balance between a model that is too simple and one that is too complex.
- High Bias (Underfitting): The model is too simple and fails to capture the underlying patterns in the data. It's like using a straight line to model a sine wave. It will perform poorly on both the data it was trained on and new data.
- High Variance (Overfitting): The model is too complex and learns the training data too well, including the noise. It's like memorizing the answers to a practice exam but being unable to solve slightly different problems on the real test. It performs great on training data but fails on new, unseen data.
Your goal as an engineer is to find the sweet spot a model complex enough to capture the signal but simple enough to ignore the noise and generalize to new situations. This is a cornerstone of any effective machine learning roadmap.
2. Evaluation Metrics: Moving Beyond Accuracy
If you build a model to detect a rare disease that only affects 0.1% of the population, a model that simply predicts "no disease" every time will be 99.9% accurate! But it's completely useless. This is why accuracy is often a trap. You need more nuanced metrics.
- Precision: Of all the times the model predicted "positive," how many were correct? (High precision means few false positives).
- Example: In a spam filter, high precision is crucial. You'd rather one spam email get through (false negative) than have an important client email go to spam (false positive).
- Recall (Sensitivity): Of all the actual positive cases, how many did the model correctly identify? (High recall means few false negatives).
- Example: In medical screening, high recall is paramount. You want to catch every potential case of the disease, even if it means some healthy people get a false alarm (false positive) and require a follow up test.
- F1 Score: The harmonic mean of precision and recall. It provides a single score that balances both concerns, which is useful when you need a compromise.
- AUC ROC Curve: A powerful metric that visualizes a classifier's performance across all classification thresholds, giving you a comprehensive view of its capabilities.
Mastering these core concepts the three paradigms of learning, the bias variance tradeoff, and robust evaluation is the most significant leap you will take in this extensive AI learning roadmap for software professionals. You're no longer just using tools; you're understanding the principles that make them work, preparing you to build, diagnose, and deploy truly intelligent systems. The next phase will involve taking this theoretical knowledge and applying it, building your first end to end projects and perhaps even dipping your toes into the world of deep learning fundamentals.
Phase 3: Unlocking the Power of Deep Learning Fundamentals
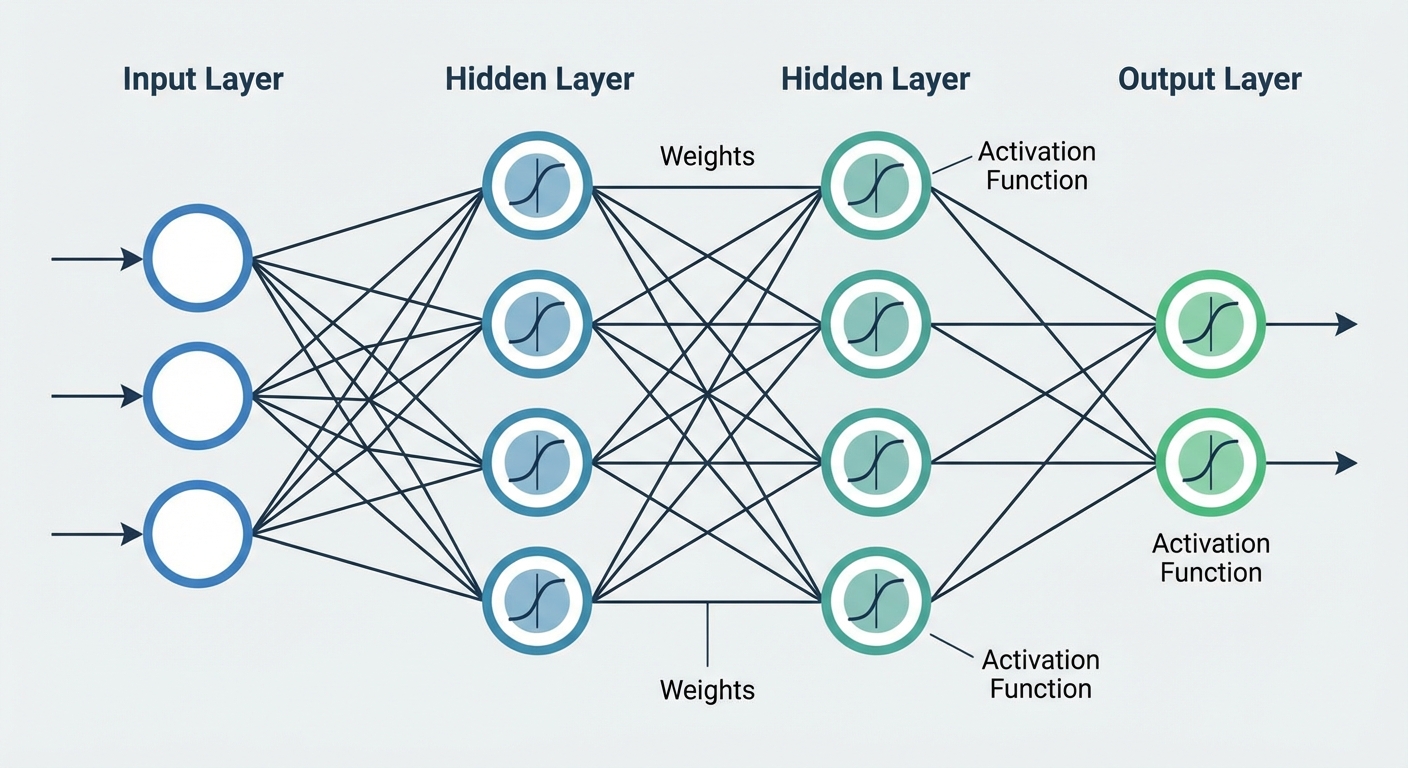
Having mastered the structured world of classical machine learning in Phase 2, you're now ready to venture into the domain that powers today's most breathtaking AI achievements. This is where your journey on this AI learning roadmap truly accelerates. Deep learning moves beyond explicit feature engineering and allows models to learn complex, hierarchical patterns directly from raw data. For software engineers, this phase is particularly exciting; it’s where you’ll build systems that can see, read, and understand the world in ways that mirror human intuition.
From Perceptrons to Multi Layer Networks: The Blueprint of the AI Brain
At the heart of deep learning is the artificial neural network, an architecture inspired by the human brain. The simplest unit is the perceptron, a single "neuron" that takes multiple inputs, applies weights to them, and "fires" if the sum exceeds a certain threshold. Think of it as a simple decision maker. While a single perceptron is limited it can only solve linearly separable problems its true power is unleashed when we stack them together.
This is how we get a Multi Layer Perceptron (MLP), the foundational deep learning model. By arranging neurons in layers an input layer, one or more "hidden" layers, and an output layer the network can learn incredibly complex, non linear relationships in data.
But how does it learn? Through a process called backpropagation.
- Forward Pass: Input data is fed through the network, and each neuron passes its output to the next layer until a final prediction is made.
- Error Calculation: The network's prediction is compared to the actual value, and an "error" or "loss" is calculated.
- Backward Pass (Backpropagation): The magic happens here. The error is propagated backward through the network, layer by layer. Each neuron's weights are adjusted based on their contribution to the total error.
Imagine it as a team of engineers debugging a complex system. The final output is wrong, so the error report is sent back down the chain of command. Each engineer (neuron) adjusts their component (weight) slightly to correct their part of the problem. This iterative process of forward and backward passes, repeated thousands of times, is how a neural network learns. Mastering these deep learning fundamentals is a non negotiable step in your AI career path.
Convolutional Neural Networks (CNNs): Teaching Machines to See
How does your phone recognize your face or a self driving car identify a pedestrian? The answer is almost always a Convolutional Neural Network (CNN). While you could technically feed image pixels into an MLP, it's incredibly inefficient and loses crucial spatial information. CNNs are specifically designed for grid like data, like images.
Their architecture is built on two key concepts:
- Filters (or Kernels): These are small matrices that slide across the input image, performing a convolution operation. Each filter is designed to detect a specific feature, like an edge, a corner, or a patch of color. In the initial layers, they detect simple features. As you go deeper, the network combines these to recognize more complex patterns like eyes, wheels, or text.
- Pooling Layers: After a convolution layer detects features, a pooling layer reduces the spatial dimensions of the feature map. This makes the network more efficient and helps it recognize an object regardless of where it appears in the image (a property called translation invariance).
A typical CNN architecture alternates between convolution and pooling layers, progressively learning more abstract features until a final set of fully connected layers makes a classification. This is the core technology behind image classification, object detection, and medical image analysis, making it a vital skill for AI for software developers working in these fields.
Recurrent Neural Networks (RNNs) & LSTMs: Understanding Sequences
Not all data is static. What about stock prices, sentences in a language, or sensor readings over time? For this sequential data, where order matters, we turn to Recurrent Neural Networks (RNNs).
An RNN has a "memory." When processing an element in a sequence, it considers not only the current input but also the information it learned from the previous elements. It does this by having a hidden state that is passed from one time step to the next, creating a loop.
However, standard RNNs suffer from the "vanishing gradient problem" their short term memory makes it difficult to learn long range dependencies. For example, in the sentence "The clouds, which had been gathering all morning, finally opened up and it started to rain," a simple RNN might forget "clouds" by the time it reaches "rain."
Enter Long Short Term Memory (LSTM) networks. LSTMs are a special type of RNN with a more sophisticated memory cell. They use a system of "gates" (an input gate, an output gate, and a forget gate) to regulate the flow of information, allowing them to decide what to store, what to discard, and what to read from their long term memory. This makes them exceptionally good at tasks like:
- Natural Language Processing (NLP): Machine translation, sentiment analysis, and chatbots.
- Time Series Analysis: Financial forecasting and anomaly detection.
- Speech Recognition: Converting spoken words into text.
Essential Deep Learning Frameworks: TensorFlow vs. PyTorch
As a software engineer, choosing the right tool is second nature. In the world of deep learning, the two dominant frameworks are TensorFlow and PyTorch.
| Feature | TensorFlow (Google) | PyTorch (Meta) |
|---|---|---|
| API Style | More declarative. Defines the entire computation graph first. | More imperative and "Pythonic." The graph is defined dynamically as code runs. |
| Ecosystem | Mature and extensive. Includes tools like TensorFlow Extended (TFX) for end to end production pipelines. | Strong and rapidly growing, especially in the research community. |
| Deployment | Traditionally seen as stronger for production with tools like TensorFlow Serving. | Has made significant strides with TorchServe and ONNX compatibility. |
| Learning Curve | Can be steeper, especially with the full Keras and TensorFlow APIs. | Generally considered more intuitive and easier to debug for beginners. |
Our recommendation for your machine learning roadmap: Start with PyTorch. Its Python native feel makes experimentation and debugging more intuitive, which is invaluable when you learn machine learning concepts. However, be prepared to encounter TensorFlow in enterprise environments, especially for large scale deployment.
Understanding Transfer Learning: The Ultimate Shortcut
You don't need to be Google or Meta to build powerful deep learning models. Transfer learning is a transformative technique that allows you to leverage the work of others. The core idea is to take a model that has been pre trained on a massive dataset (like ImageNet, with over 14 million images) and adapt it for your own, often much smaller, dataset.
The process is simple:
- Load a state of the art pre trained model (e.g., ResNet50 for images or BERT for text).
- "Freeze" the early layers, which have already learned to detect general features (edges, textures, grammar rules).
- Replace the final classification layer with a new one tailored to your specific problem.
- Train only the new, unfrozen layers on your custom data.
This approach dramatically reduces training time, requires significantly less data, and often results in higher accuracy than training a model from scratch. For any practical application, transfer learning is the go to strategy, making it a cornerstone of this extensive AI learning roadmap for software professionals.
The Generative AI Revolution: A Developer's Guide to Transformers and LLMs
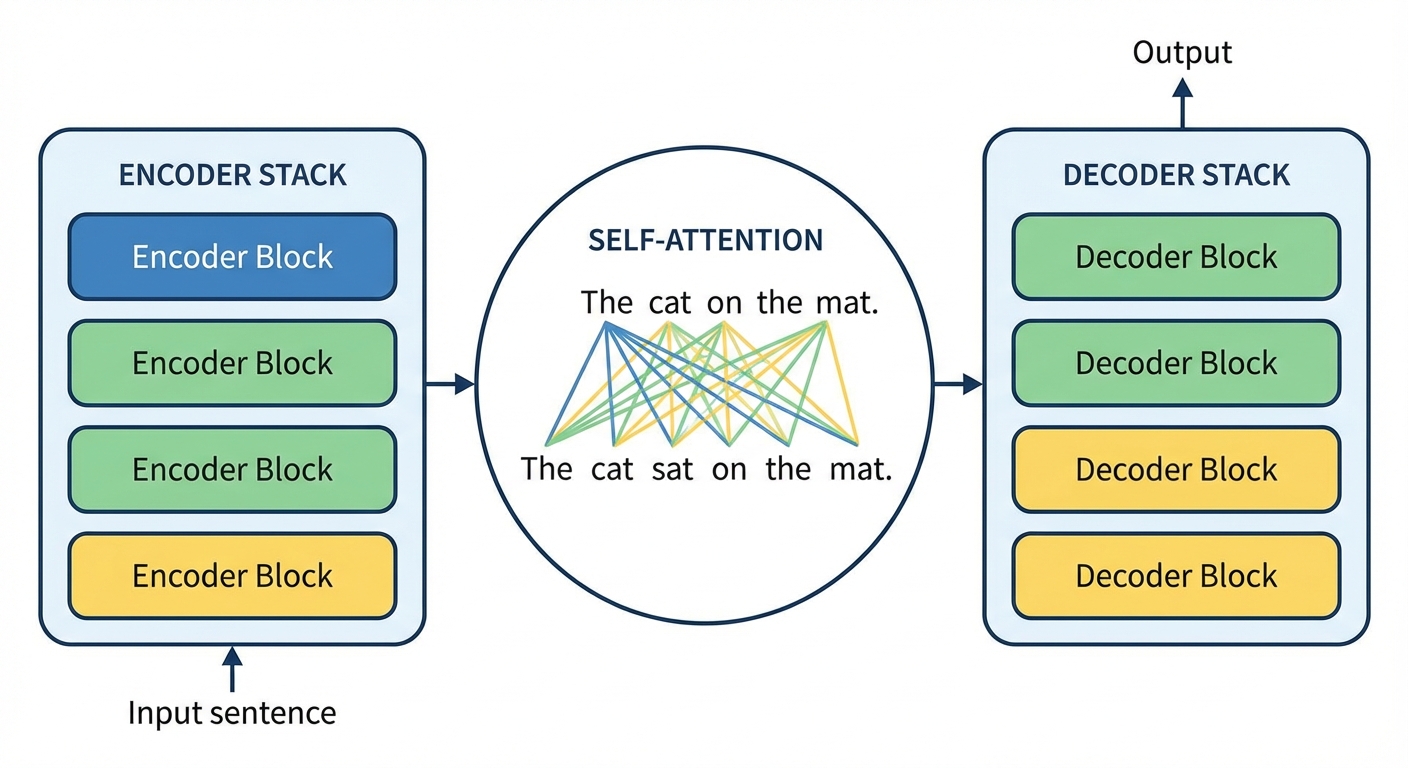
Having journeyed through the core principles of deep learning, you now stand at the precipice of the most transformative technology of our era: Generative AI. This is where your foundation in neural networks converges with cutting edge architecture to create systems that can write, code, design, and reason. For any developer navigating their AI career path, mastering this domain is no longer optional it's the key to building the next generation of intelligent applications. This phase of your AI learning roadmap is about moving from understanding models to commanding them.
The Transformer Architecture: The Engine of Modern AI
Before 2017, processing sequential data like text was dominated by Recurrent Neural Networks (RNNs) and LSTMs. While powerful, they struggled with long range dependencies understanding the connection between words far apart in a long document. The game changed with the seminal paper, "Attention Is All You Need," which introduced the Transformer architecture. This model didn't just improve on existing benchmarks; it created an entirely new paradigm and is one of the most critical deep learning fundamentals to grasp today.
The magic of the Transformer lies in three core concepts:
-
Self Attention Mechanism: This is the heart of the Transformer. Imagine reading the sentence: "The robot picked up the ball because it was heavy." To understand what "it" refers to, you instinctively weigh the importance of other words. "Robot" and "ball" are highly relevant, while "picked" and "up" are less so. Self attention allows the model to do the same thing computationally. For every word it processes, it generates a score for every other word in the input, determining how much "attention" to pay to them. This ability to dynamically weigh the importance of different parts of the input allows Transformers to capture complex context, no matter the distance between words.
-
Positional Encoding: One drawback of abandoning the sequential nature of RNNs is that the model loses the inherent order of words. "The dog chased the cat" means something very different from "The cat chased the dog." Positional encodings solve this. They are vectors of numbers added to each word's embedding that give the model a unique "signal" about its position in the sequence. This allows the self attention mechanism to consider word order when calculating context.
-
Encoder Decoder Structure: The original Transformer had two parts. The Encoder reads the input text and builds a rich, context aware numerical representation. The Decoder takes that representation and generates the output text, one word at a time. Many modern LLMs, like the GPT (Generative Pre trained Transformer) family, are "decoder only" models, optimized specifically for text generation.
Understanding these building blocks is crucial for any professional on an extensive AI learning roadmap for software professionals, as they form the basis for nearly every state of the art model you'll encounter.
Working with LLMs: From Theory to Practice
As a software engineer, this is where your skills truly shine. You don't need to build a Transformer from scratch to leverage its power. The modern landscape of AI for software developers is dominated by powerful, pre trained models accessible via APIs and open source libraries.
- API based Models: Companies like OpenAI (GPT 4o, GPT 3.5), Anthropic (Claude 3 family), and Google (Gemini family) offer robust APIs. Your experience with REST APIs, handling JSON, and managing API keys is directly applicable. You can integrate sophisticated language capabilities into your applications with just a few lines of code.
# A simplified example using OpenAI's Python client from openai import OpenAI client = OpenAI(api_key="YOUR_API_KEY") response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Explain the concept of self-attention in one sentence."} ] ) print(response.choices[0].message.content) - Open Source Models: The open source community is a vibrant and powerful force. Models like Meta's Llama 3 and Mistral AI's Mistral and Mixtral models offer performance that rivals or even exceeds proprietary alternatives. Using your skills in Python for AI, you can run these models locally or on your own cloud infrastructure using libraries like Hugging Face's
transformers, giving you complete control over your data and costs.
Prompt Engineering vs. Fine Tuning: Choosing the Right Tool
Once you have access to a model, how do you get it to perform a specific task? You have two primary strategies, and knowing when to use each is a hallmark of an effective AI practitioner.
Prompt Engineering is the art and science of crafting inputs (prompts) to guide an LLM to produce the desired output. It leverages the model's existing knowledge through "in context learning." This is your first and most powerful tool. It's fast, cheap, and often surprisingly effective.
- When to use it: For most general tasks like summarization, translation, classification, and creative content generation. Start here, always.
- Example: Instead of asking, "Summarize this text," a better prompt would be, "Summarize this technical report for a non technical executive. Focus on the key business implications and actionable outcomes. The summary should be a 3 bullet point list."
Fine Tuning is the process of further training a pre trained model on a smaller, domain specific dataset. This doesn't teach the model new general knowledge but adapts its style, tone, and knowledge for a specialized task.
- When to use it: When prompt engineering isn't enough. Use it when you need the model to adopt a very specific persona, understand niche jargon, or follow a complex, proprietary format consistently.
- Example: Fine tuning a model on thousands of your company's internal customer support tickets to create a chatbot that understands your product's specific issues and speaks in your brand's voice.
Introduction to RAG: Bridging the Knowledge Gap
One of the biggest limitations of LLMs is that their knowledge is frozen at the time of their training. They don't know about recent events, and they certainly don't know about your company's private documents. This is where Retrieval Augmented Generation (RAG) comes in.
RAG is a powerful architectural pattern that makes LLMs work with external data. It's a cornerstone of modern AI for software engineers. The process is simple yet profound:
- Retrieve: When a user asks a question, the system first searches an external knowledge base (like a vector database containing your company's documentation) for relevant information. This step leverages classic information retrieval and data science basics.
- Augment: The relevant snippets of information are then "augmented" by adding them to the user's original prompt.
- Generate: This combined prompt (original question + retrieved context) is sent to the LLM, which then generates an answer based on the provided information.
RAG transforms an LLM from a general purpose know it all into a domain specific expert, capable of answering questions about private or real time data without the need for costly fine tuning.
Beyond Text: The Rise of Multi modal AI
The revolution isn't confined to text. The latest generation of models, like OpenAI's GPT 4o and Google's Gemini, are multi modal. They can understand and process a seamless combination of text, images, audio, and even video.
For a developer, this unlocks a universe of possibilities:
- Build an application where a user can upload a picture of their refrigerator's contents and get a recipe.
- Create a code assistant that can look at a screenshot of a web design and generate the corresponding HTML and CSS.
- Develop a tool that can listen to a meeting recording and produce a structured summary with action items.
As you continue to learn machine learning, embracing multi modality will be key to staying at the forefront of innovation. This is the next step in your machine learning roadmap, moving from single data type models to systems that perceive and interact with the world in a much more human like way.
From Laptop to Production: A Software Engineer's Guide to MLOps
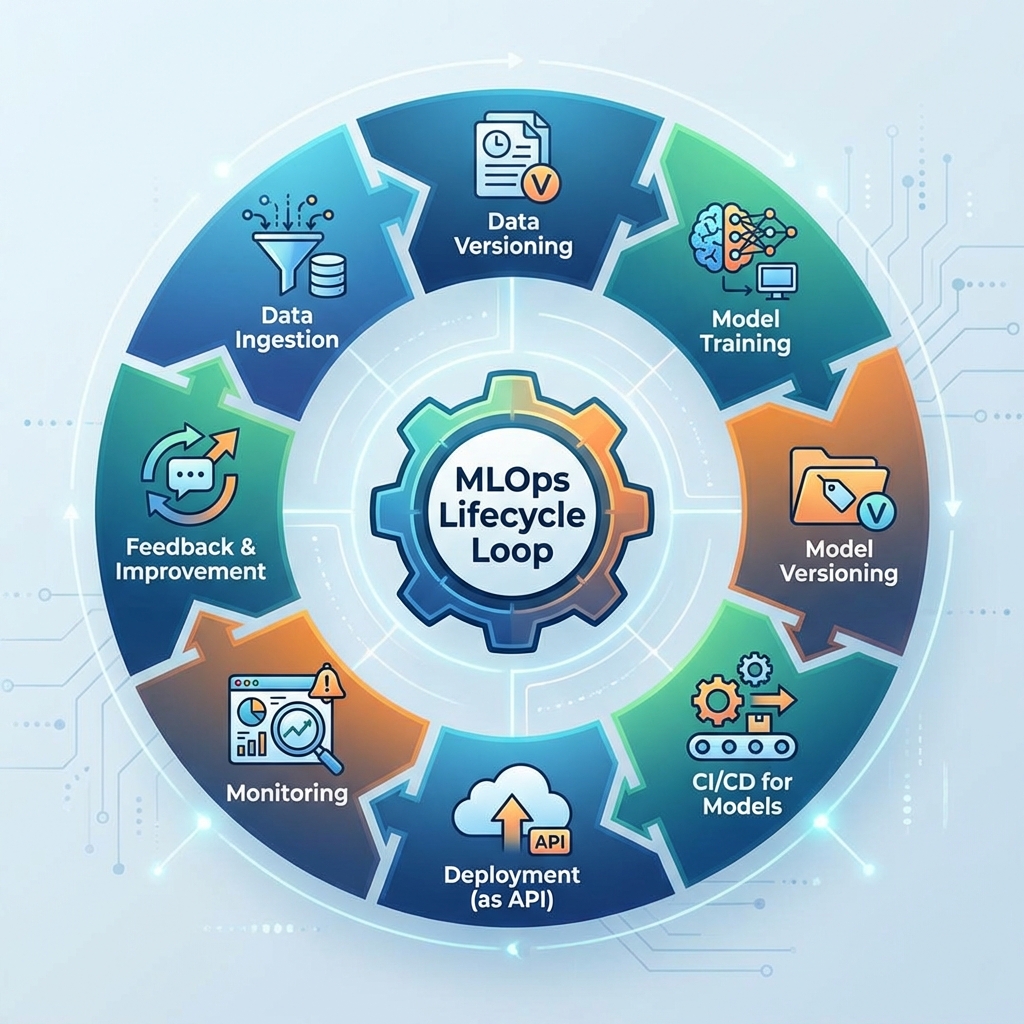
You've journeyed from the mathematical bedrock of AI to the towering heights of Generative AI. You've trained models, tuned hyperparameters, and seen the magic of a neural network come to life on your laptop. But here's the unvarnished truth: a model that only exists in a Jupyter Notebook is a brilliant science experiment, not a valuable product. This is where your software engineering instincts kick in, and it's where the world of AI for software engineers truly comes alive.
Welcome to MLOps (Machine Learning Operations), the discipline that transforms your models from fragile prototypes into robust, scalable, and reliable software systems. If DevOps is about bridging the gap between development and operations, MLOps is its specialized counterpart, built to handle the unique complexities of the machine learning lifecycle. This is the final, crucial stage in your AI learning roadmap, turning theoretical knowledge into tangible impact.
The Core Pillars of MLOps: CI/CD/CT
For software developers, CI/CD is second nature. MLOps adopts this philosophy and adds a critical third pillar to address the dynamic nature of data and models.
- Continuous Integration (CI): This is more than just testing your Python code. In an ML context, CI involves automated checks for code quality, data validation (ensuring new data conforms to the expected schema and distribution), and model validation (testing the model's performance on a predefined test set).
- Continuous Deployment (CD): Once a model passes the CI phase, CD pipelines automate its packaging (e.g., into a Docker container) and deployment to a production environment. This could involve a canary release, where the new model serves a small fraction of traffic, or a full rollout.
- Continuous Training (CT): This is the game changer and the key differentiator from traditional DevOps. CT is the practice of automatically retraining your model when new data becomes available or when the model's performance in production degrades. This creates a feedback loop that keeps your model relevant and accurate over time.
Your MLOps Toolkit: Essential Frameworks and Platforms
Navigating the MLOps landscape involves combining specialized tools to manage the end to end process. Think of this as the ultimate workshop for any professional on an AI career path.
- Data and Model Versioning (DVC): You use Git for code, but Git can't handle massive datasets. Tools like DVC (Data Version Control) work alongside Git to version your data and models, ensuring every experiment is 100% reproducible.
- Experiment Tracking (MLflow): When you're running dozens of experiments, how do you track which parameters, code, and data version produced the best model? MLflow is an open source platform to log metrics, parameters, and artifacts for every run, making it easy to compare results and select the best model for deployment.
- Containerization (Docker): A concept familiar to every modern developer. Docker allows you to package your model, its dependencies, and the inference code into a standardized, portable container. This solves the "it works on my machine" problem for good.
- Orchestration (Kubernetes): Once your model is in a Docker container, Kubernetes (K8s) is the industry standard for deploying, scaling, and managing it in production. It handles load balancing, auto scaling, and self healing, ensuring your model serving endpoint is always available.
- End to End Platforms (Kubeflow, SageMaker, Vertex AI): For a more integrated experience, platforms like Kubeflow (which runs on Kubernetes), Amazon SageMaker, and Google's Vertex AI provide a unified suite of tools to manage the entire lifecycle, from data preparation to monitoring. Mastering one of these is a key part of any extensive AI learning roadmap for software professionals.
CI/CD for Machine Learning: An Automated Workflow
Imagine an automated pipeline that brings CI, CD, and CT together. This is the holy grail of MLOps.
- Trigger: A developer pushes new feature engineering code, or a new batch of labeled data lands in cloud storage.
- CI Phase: A CI server (like Jenkins or GitHub Actions) kicks off a job. It runs unit tests, validates the new data's schema, and performs a quick model training run to ensure nothing is broken.
- CT Phase: The pipeline triggers a full training job on the new data, using a tool like Kubeflow Pipelines to orchestrate the steps. The experiment's results are logged to MLflow.
- Evaluation: The newly trained model is automatically evaluated against the currently deployed model on a "golden" holdout dataset.
- CD Phase: If the new model shows a statistically significant performance improvement, the CD process begins. The model is packaged into a Docker container, pushed to a registry, and deployed to your Kubernetes cluster, perhaps starting as a canary release.
Model Serving and Deployment Patterns
"Deployment" isn't a single action; it's a strategy tailored to your use case.
- Real time Inference: The model is exposed via a REST API. When a request comes in, the model provides a prediction in milliseconds. This is ideal for fraud detection, product recommendations, and dynamic pricing.
- Batch Processing: The model runs on a schedule (e.g., nightly) to process large volumes of data at once. This is perfect for generating daily sales forecasts, customer segmentation reports, or personalizing email campaigns.
- Edge Deployment: The model is optimized and deployed to run directly on a user's device, like a smartphone or an IoT sensor. This provides ultra low latency and works offline, essential for applications like live camera filters or predictive maintenance on factory equipment.
The Final Mile: Monitoring for Data Drift and Model Decay
Once your model is live, the job is far from over. The real world is not static. This is a concept that moves beyond data science basics into the reality of production systems. You must monitor for two silent killers:
- Data Drift: This occurs when the statistical properties of the data your model sees in production (e.g., user demographics, purchasing habits) change from the data it was trained on. A model trained on pre pandemic shopping data will likely perform poorly in a post pandemic world.
- Model Decay (or Concept Drift): This is when the underlying relationships in the data change. For example, a new competitor might enter the market, changing what features predict customer churn.
Effective monitoring systems track these drifts, alert your team when performance degrades, and can even automatically trigger the CT pipeline to retrain the model on fresh data, closing the MLOps loop. As you continue to learn machine learning, remember that a model is a living product that requires continuous care and maintenance.
Building Your AI Project Portfolio to Showcase Your Skills
You've journeyed through the theoretical landscapes of machine learning, deep learning, and MLOps. Now, it's time to build the monuments that prove your mastery. In the world of AI, your GitHub profile is your new resume, and a portfolio of thoughtful, end to end projects is the most powerful testament to your skills. This is the capstone of your AI learning roadmap, transforming abstract knowledge into tangible, career defining assets.
Hiring managers aren't looking for someone who can follow a tutorial; they're looking for a problem solver. This section provides an actionable strategy to build a portfolio that gets you noticed.
Strategy Over Quantity: The Power of Three
The first rule of building an effective AI portfolio is to reject the "more is better" mindset. A portfolio with ten different projects based on the Iris or Titanic datasets signals imitation, not innovation. Recruiters have seen these a thousand times. Instead, focus on creating three high quality, end to end projects.
Why three?
- Demonstrates Depth: A single project could be a fluke. Three shows a pattern of competence and the ability to tackle different types of problems.
- Showcases the Full Lifecycle: A quality project isn't just a Jupyter Notebook with a
model.fit()call. It demonstrates your ability to define a problem, acquire and clean data, experiment with models, and, most importantly, make the model accessible. - Respects a Recruiter's Time: A hiring manager is more likely to explore one of your three compelling projects in depth than to skim through ten generic ones.
This focused approach is a cornerstone of a successful AI career path, proving you can deliver value from concept to completion.
Finding Your Niche: Project Idea Generation
The most compelling projects are born from genuine curiosity. To stand out, move beyond the well trodden path of Kaggle's introductory competitions and find unique problems to solve.
Here’s how to brainstorm ideas:
- Align with Your Passions: Are you a gamer? Scrape data from a gaming API to predict match outcomes. A musician? Use audio data to classify musical genres or generate simple melodies. A finance enthusiast? Analyze sentiment from news articles to correlate with market movements. Projects fueled by your interests are more engaging for you to build and for others to review.
- Explore Public Datasets: Go beyond the usual suspects. Websites like
data.gov, the UCI Machine Learning Repository, or GitHub lists like "Awesome Public Datasets" are goldmines for unique data. - Create Your Own Data: As an AI for software engineer, you have a unique advantage: you can build systems. Write a script to scrape data from a website (ethically and respecting
robots.txt), or use public APIs from services like Spotify, Reddit, or Twitter to collect a novel dataset that no one else has.
The End to End Project Blueprint
Structure each of your portfolio projects to tell a complete story. This blueprint showcases your technical breadth, from understanding data science basics to deploying a functional application.
-
Problem Definition & Data Acquisition:
- Goal: Clearly articulate the problem you are solving and why it's interesting.
- Data Source: Detail where your data came from (API, web scraping, public repository) and how you collected it.
-
Exploratory Data Analysis (EDA) & Preprocessing:
- Investigation: This is where you demonstrate your intuition. Use libraries like Pandas, Matplotlib, and Seaborn to clean the data, handle missing values, and visualize distributions. What initial insights did you uncover?
- Preparation: Explain your feature engineering and preprocessing steps (e.g., scaling, encoding categorical variables).
-
Modeling & Experimentation:
- Baseline: Start with a simple model to establish a baseline performance.
- Iteration: This is where you apply your knowledge of deep learning fundamentals or classical ML algorithms. Document the different models you tried. Why did you choose a Random Forest over a Logistic Regression, or a Transformer over an LSTM? Show your hyperparameter tuning process. This iterative journey is central to how you learn machine learning in a practical sense.
-
Evaluation:
- Metrics: Choose appropriate evaluation metrics (e.g., Accuracy, F1 Score, RMSE) and justify your choice.
- Results: Present your results clearly, using visualizations like confusion matrices or ROC curves. Discuss the model's strengths and weaknesses.
-
Deployment & Presentation:
- The Differentiator: This is where AI for software developers truly shine. Don't let your model die in a notebook.
- Build an API: Wrap your trained model in a simple API using Flask or FastAPI.
- Create a UI: Build a simple, interactive web app with a tool like Streamlit or Gradio so others can easily test your model.
- Containerize: Use Docker to containerize your application, making it easy to run anywhere.
Documenting Your Work: Tell Your Story
A brilliant project with poor documentation is like a masterpiece locked in a dark room. Your ability to communicate your work is as important as the work itself.
- The README is King: Your project's
README.mdis the front door. It should be a comprehensive guide that includes a project summary, the problem statement, setup instructions, a summary of your results, and a link to your deployed app or a blog post. - Write Clean Code: Adhere to Python for AI best practices. Your code should be well structured, commented, and readable. Your software engineering background is your superpower here use it.
- Write a Blog Post: For each project, write an accompanying blog post. This is your chance to build a narrative. Explain your thought process, the challenges you overcame, and what you learned. This transforms a code repository into a compelling case study and is the final piece in an extensive AI learning roadmap for software professionals. It proves you're not just a coder; you're a problem solver who can communicate complex ideas effectively.
Navigating the AI Career Path and the Imperative of Responsible AI
You've journeyed through the entire AI learning roadmap, from the mathematical bedrock to the towering heights of MLOps. With a powerful portfolio in hand, you're no longer just a software engineer; you're an architect of intelligent systems. Now, it's time to navigate the final frontiers: the job market and the profound ethical landscape that defines a true AI professional. This is where your technical skills meet real world impact and responsibility.
Decoding the AI Job Landscape
The term "AI Engineer" is often an umbrella for a variety of specialized roles. Understanding the nuances of the AI career path is crucial for targeting your job search effectively. While titles can vary between companies, they generally fall into these categories:
- Machine Learning Engineer: This role is the most direct evolution for a software engineer. ML Engineers are the builders who productionize models. They are experts in MLOps, system architecture, and writing robust, scalable code to serve models to millions of users. Your software background is your superpower here.
- Applied Scientist: This role leans more towards research and development. Applied Scientists often have a stronger background in statistics and mathematics. They experiment with novel architectures, read academic papers, and develop new algorithms to solve complex business problems that don't have off the shelf solutions.
- Data Scientist: While there's significant overlap, a Data Scientist often focuses more on analysis, statistical modeling, and extracting business insights from data. Their work informs strategy and may involve building predictive models, but often with less emphasis on the production engineering aspect compared to an ML Engineer. Understanding data science basics is foundational for all these roles.
- AI Product Manager: For those who love strategy and the big picture, this role involves defining the vision for AI products. They work with stakeholders, engineers, and designers to decide what to build, why it matters, and how to measure its success.
Cracking the AI/ML Interview
An AI/ML interview is a multi faceted challenge designed to test your theoretical knowledge, practical skills, and problem solving mindset. Expect a process that includes:
- Technical Screening: Be prepared to discuss deep learning fundamentals, algorithms, and data structures. You might be asked to implement a simple algorithm in Python for AI or answer questions about probability and statistics.
- System Design: This is where AI for software engineers truly shines. A common prompt is, "Design a recommendation system for Netflix" or "Design a spam filter for Gmail." You'll be expected to discuss data ingestion, feature engineering, model selection trade offs (e.g., latency vs. accuracy), A/B testing, and how you'd monitor the system in production.
- Behavioral Questions: Your portfolio projects are your best ammunition here. Be ready to articulate the "why" behind your technical decisions, discuss how you handled ambiguous data, and explain how you measured the success of your models.
The AI Ethics Toolkit for Every Developer
Building powerful AI systems comes with an immense responsibility. As an engineer, you are the first line of defense against creating systems that are harmful, biased, or unfair. This isn't an afterthought; it's a core engineering requirement.
- Identifying and Mitigating Bias: AI models learn from data. If the data reflects historical societal biases (e.g., hiring data that favors one demographic), your model will learn and amplify those biases. The first step is to audit your data for skews and imbalances. Techniques like data augmentation or re weighting can help mitigate this.
- Model Explainability: How can you trust a model if you don't know why it made a particular decision? This is where model explainability (or XAI) comes in. Tools like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model agnostic Explanations) are critical for peering inside the "black box." They help you understand which features most influenced a prediction, which is essential for debugging, building user trust, and ensuring fairness.
Principles of Responsible AI Development
Embracing a responsible AI mindset means building systems that are:
- Fair: The system's outcomes do not reinforce unfair societal biases.
- Transparent: You can explain how the system works and why it makes its decisions.
- Secure: The system is robust against adversarial attacks designed to manipulate its outcomes.
- Accountable: There are clear lines of ownership and responsibility for how the system operates.
Your Transition from Software to AI Engineer
So, how do you make the final leap? You've already done the hard work by following this extensive AI learning roadmap for software professionals. The path is clear:
- Leverage Your Strengths: Market your software engineering expertise system design, clean code, testing, and deployment as your core advantage.
- Bridge the Gap with Projects: Your portfolio is the proof that you've successfully integrated ML knowledge with your engineering skills.
- Lead with Responsibility: In interviews and on the job, demonstrate your understanding of AI ethics. This maturity and foresight will set you apart and mark you as a leader in the field.
You have the skills, the roadmap, and the perspective. The world of AI is not just a new career path; it's an opportunity to build a more intelligent, efficient, and equitable future. Go build it.
Your Actionable AI Roadmap: A 6 Month vs. 12 Month Learning Plan
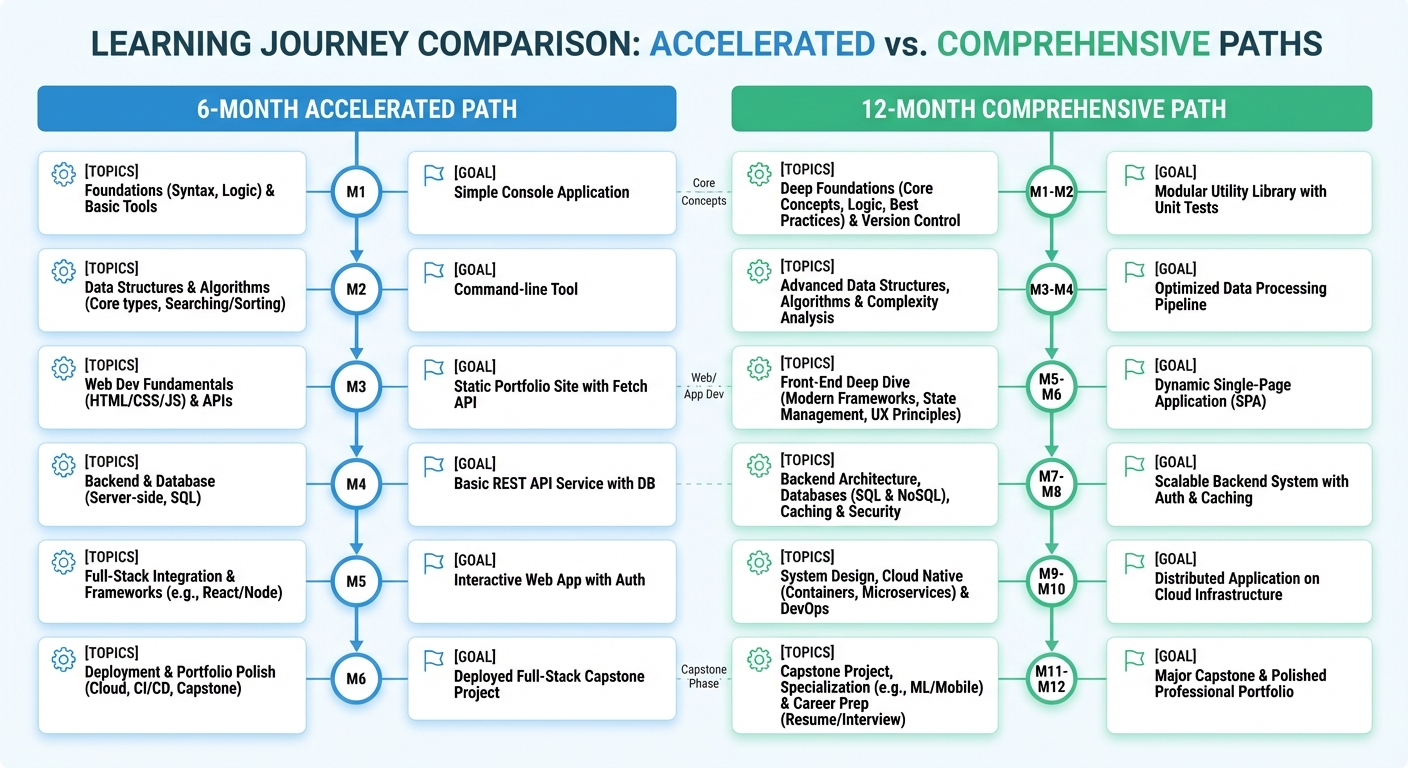
You've journeyed through the core concepts, from the mathematical bedrock to the complexities of MLOps. Now, it's time to transform that knowledge into a concrete strategy. The path you choose from here depends on your goals, timeline, and existing expertise. This is where your personalized AI learning roadmap takes shape.
We've consolidated everything into two distinct, actionable plans. Whether you're sprinting to upskill for an immediate opportunity or embarking on a marathon to achieve deep mastery, these timelines will provide the structure you need to succeed.
The 6 Month Accelerated Plan: The Sprint to Production
This high intensity track is designed for experienced software developers who are comfortable with rapid, "just in time" learning. The focus is on practical application, modern frameworks, and quickly becoming productive in a professional AI environment. This 6 month AI learning plan for programmers prioritizes building with today's most relevant tools over deep theoretical exploration.
Who It's For:
- Senior software engineers with a strong foundation in computer science and system design.
- Developers on a tight deadline for a new project or role.
- Professionals who learn best by doing and want to build a major portfolio piece quickly.
Monthly Breakdown:
-
Months 1 2: Rapid Foundations & Core ML Application
- Focus: Quickly bridge the gap from software engineering to data centric thinking. This isn't about learning Python; it's about mastering Python for AI specifically NumPy, Pandas, and Matplotlib for data manipulation and visualization.
- Action Items:
- Complete a crash course on Linear Algebra and Calculus essentials, focusing on intuition over proofs.
- Sprint through core machine learning algorithms (e.g., Linear/Logistic Regression, Decision Trees, SVMs) using Scikit learn. The goal is to understand when and why to use them, not to implement them from scratch.
- Project: Build a simple predictive model on a Kaggle dataset.
-
Months 3 4: Deep Learning & The Generative AI Revolution
- Focus: Dive directly into the tools that power modern AI. You'll bypass some classical theory to get hands on with neural networks, Transformers, and Large Language Models (LLMs).
- Action Items:
- Learn a modern deep learning framework (PyTorch is highly recommended) through a practical course like fast.ai.
- Master the Hugging Face ecosystem (Transformers, Datasets, Tokenizers).
- Implement key Generative AI techniques like fine tuning a pre trained model (e.g., GPT 2 or a smaller T5 model) and building a Retrieval Augmented Generation (RAG) system.
-
Months 5 6: MLOps & Capstone Project
- Focus: Leverage your software engineering strengths to productionize your models. This phase solidifies your value as an AI for software engineer who can bridge the gap between research and reality.
- Action Items:
- Containerize your models with Docker.
- Build a simple CI/CD pipeline for model training and deployment using GitHub Actions.
- Deploy your model as an API endpoint using FastAPI and a cloud service (AWS SageMaker, Google Vertex AI, or Hugging Face Spaces).
- Consolidate all your learning into a single, impressive capstone project that showcases your end to end skills.
Recommended Resources:
- Courses: fast.ai's "Practical Deep Learning for Coders," Hugging Face's NLP Course.
- Books: "Designing Data Intensive Applications" by Martin Kleppmann (for the systems mindset).
- Communities: The fast.ai forums, local AI/ML meetups.
The 12 Month Comprehensive Plan: The Marathon to Mastery
This path is for those who want to build a more robust, first principles understanding of AI. It's a more paced approach that allows for deeper dives into theory, mathematics, and a wider range of algorithms. This extensive AI learning roadmap for software professionals builds a foundation that will remain relevant for decades.
Who It's For:
- Developers who prefer a structured, academic approach to learning.
- Those aiming for more specialized or research adjacent roles.
- Anyone who wants to truly understand the "why" behind the algorithms, not just the "how."
Quarterly Breakdown:
-
Quarter 1 (Months 1 3): The Unshakable Bedrock
- Focus: A rigorous and deep dive into the mathematical foundations and Data science basics. No shortcuts here.
- Action Items:
- Complete university level courses in Linear Algebra, Multivariate Calculus, and Probability & Statistics.
- Master Python's scientific computing stack (NumPy, Pandas, Scikit learn) from the ground up.
- Work through introductory data analysis projects.
-
Quarter 2 (Months 4 6): Classical Machine Learning Mastery
- Focus: A thorough exploration of the classical machine learning roadmap. You'll not only use the algorithms but also understand their inner workings.
- Action Items:
- Study supervised, unsupervised, and reinforcement learning paradigms in depth.
- Implement a few key algorithms (like K Nearest Neighbors or Linear Regression) from scratch to understand them intimately.
- Project 1: Build a robust classification or regression model and document your feature engineering and model selection process.
-
Quarter 3 (Months 7 9): The Deep Learning Odyssey
- Focus: Build your understanding of Deep learning fundamentals from the ground up, starting with the perceptron and moving to complex architectures.
- Action Items:
- Learn the mechanics of backpropagation, gradient descent, and activation functions.
- Build and train Convolutional Neural Networks (CNNs) for image tasks and Recurrent Neural Networks (RNNs) for sequence data.
- Project 2: Develop a computer vision or NLP project using PyTorch or TensorFlow.
-
Quarter 4 (Months 10 12): Specialization, Production, and Career Launch
- Focus: Specialize in a high demand area and prepare for your new AI career path.
- Action Items:
- Dive deep into a chosen specialization (e.g., Advanced NLP with Transformers, Computer Vision, or MLOps).
- Learn the principles of MLOps and deploy your projects to a cloud platform.
- Project 3 (Capstone): Build a sophisticated, end to end project in your area of specialization.
- Begin networking, contributing to open source AI projects, and preparing for technical interviews.
Recommended Resources:
- Courses: Andrew Ng's "Machine Learning Specialization" and "Deep Learning Specialization" on Coursera.
- Books: "The Elements of Statistical Learning" by Hastie et al., "Deep Learning with Python" by François Chollet.
- Communities: Kaggle, Papers with Code, the r/MachineLearning subreddit.
Ultimately, the best plan is the one you can stick with. Both paths lead to a rewarding career as an AI for software developer. Choose the timeline that best fits your life, learning style, and professional ambitions.
Conclusion
Key Takeaways:
- Transitioning into AI is not about abandoning your software skills, but augmenting them. Your engineering discipline is your biggest advantage.
- A successful AI learning roadmap balances foundations (Math, Python, Core ML) with modern, high impact areas like Generative AI and MLOps.
- Consistent, project based learning is the key to building a strong portfolio and making a successful career transition.
Your journey to becoming an AI augmented software engineer starts now. Pick a plan, start with Phase 1, and join the conversation in the comments below. What's the first AI project you're excited to build?
Published: January 14, 2026
Related Topics
Related Resources
Build AI Agents from Scratch with Python and Gemini: A Beginner Friendly Guide to Use Cases and Challenges
AI agents are moving beyond simple chatbots, and with Python and Gemini, beginners can now start building useful autonomous workflows faster than ever. This article introduces AI agents in a practical, beginner friendly way and shows how Python and Gemini can be used to create them from scratch. It covers the core building blocks, a simple development path, real world use cases, and the main challenges to watch for when getting started.
articleThe Agentic Shift: How Autonomous AI Will Redefine Banking, Finance, and Insurance by 2026
By 2026, the financial services industry will cross a critical threshold, moving beyond the era of AI that merely suggests to one where AI autonomously acts. This comprehensive analysis explores the impending transition from Generative to Agentic AI in the BFSI sector. We will dissect the multi trillion dollar economic impact, explore production grade use cases, and confront the profound strategic, compliance, and systemic risks that autonomous agents introduce, providing a C suite playbook for navigating this new reality.
videoSemantic Search and Retrieval-Augmented Generation (RAG)
Unlock the power of Semantic Search and Retrieval-Augmented Generation (RAG) using Generative AI. Learn how modern AI systems extract information, improve accuracy, and deliver truly contextual responses.